What is a Hypothesis Testing Planner?
A hypothesis testing planner is a structured document that defines the statistical test you will run before you run it — specifying the null and alternative hypotheses, the test type, the significance level, the sample size and what the result will mean for the project.
Running statistical tests without a plan leads to two common errors: testing the wrong hypothesis, or selecting the test based on which one gives the desired result (p-hacking). A testing planner prevents both by forcing the team to commit to the test design before seeing the data.
Hypothesis testing is used in the Analyse phase to statistically confirm or rule out suspected root causes and differences between process conditions.
When to use a Hypothesis Testing Planner
Build a hypothesis testing plan before running any statistical test. Use it when:
- You want to test whether two groups (shifts, machines, suppliers) perform differently
- You want to confirm whether a suspected cause variable is statistically related to the outcome
- You need to provide statistical evidence to a sponsor that a difference is real, not due to chance
- A pilot or before-and-after comparison needs to be statistically validated
Who should use a Hypothesis Testing Planner
- Green Belts and Black Belts — when planning and executing statistical analysis in the Analyse phase
- Black Belts and MBBs — for more complex designed experiments and multi-variable analysis
- Data Analysts and Statisticians — when designing studies to test specific hypotheses in process improvement
- Quality Engineers — when statistically validating process changes or supplier differences
Watch: a quick explainer
New to this? This short video walks you through validating a hypothesis with data — a helpful primer before you download and use the template.

How to plan a Hypothesis Test
Write the hypothesis test plan before you look at the data. Once you have seen the data, it is impossible to plan the test objectively — the data will influence what test you choose and how you interpret the result.
How to plan a Hypothesis Test — step by step
-
1Write the null hypothesis (H₀)
The null hypothesis is the default assumption — that there is no difference or no effect. Example: 'There is no difference in mean output between Shift A and Shift B.' The test tries to disprove this.
-
2Write the alternative hypothesis (H₁)
The alternative hypothesis is what you are trying to prove. Example: 'Shift A produces higher mean output than Shift B.' Specify whether the test is one-tailed (directional) or two-tailed (any difference).
-
3Choose the significance level (α)
The significance level is the probability of rejecting the null hypothesis when it is actually true (Type I error). α=0.05 (5%) is standard. Use α=0.01 for higher-stakes decisions.
-
4Select the appropriate test
Continuous data, 2 groups: 2-sample t-test or Mann-Whitney U. Continuous data, >2 groups: ANOVA or Kruskal-Wallis. Proportions: 2 proportions test. Relationships: regression or correlation. Non-normal: use non-parametric equivalent.
-
5Calculate the required sample size
Use a power analysis to determine the sample size needed to detect a difference of the magnitude you care about with 80% power. Under-powered tests miss real differences; over-powered tests find trivial differences.
-
6Run the test and record the p-value
A p-value < α means you reject the null hypothesis — the difference is statistically significant. A p-value ≥ α means you fail to reject — the data does not provide sufficient evidence of a difference.
-
7Interpret the result in practical terms
Statistical significance ≠ practical importance. A p-value of 0.001 with a difference of 0.01 days may be statistically significant but practically meaningless. State both the statistical result and the practical implication.
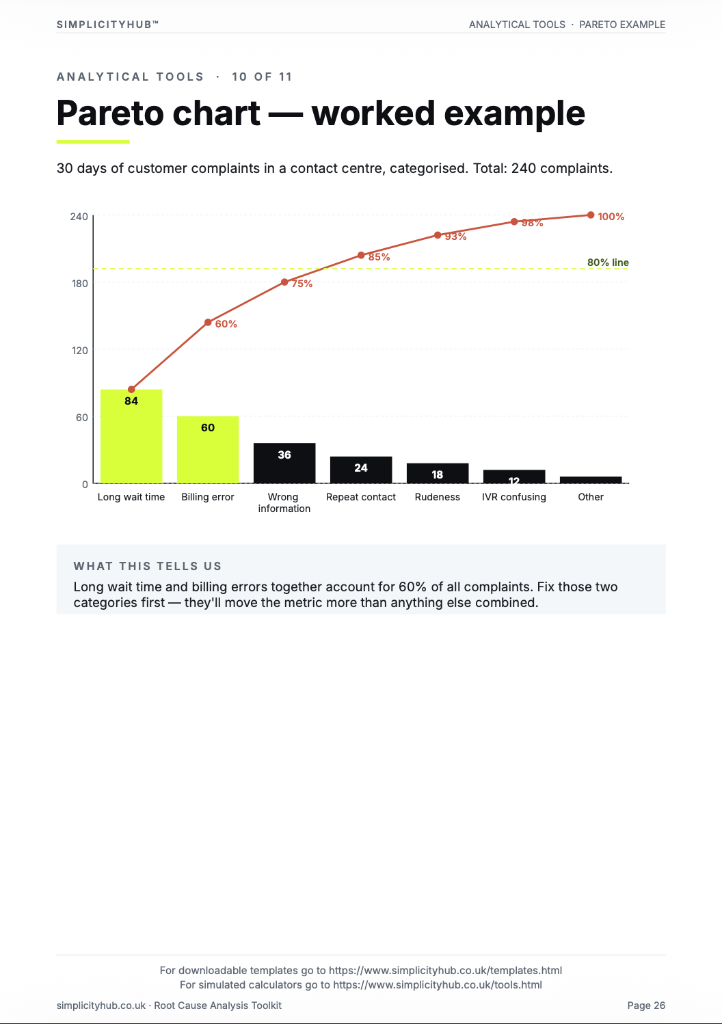
Worked example — Shift Comparison Hypothesis Test
A completed hypothesis testing plan for a shift performance comparison, showing null and alternative hypotheses, 2-sample t-test selection, α=0.05, sample size calculation and result interpretation.

Common mistakes — and how to avoid them
Not writing hypotheses before seeing the data. Defining hypotheses after looking at the data means you are confirming what you already see rather than testing what you predicted. Commit to the hypothesis before collecting or analysing data.
Using the wrong test for the data type. A t-test applied to non-normal data with small samples produces unreliable p-values. Check your data type, distribution and sample size before selecting the test.
Equating statistical significance with root cause confirmation. A statistically significant difference between two groups tells you the difference is unlikely to be due to chance. It does not tell you why the difference exists. Combine statistical evidence with process knowledge to confirm root causes.
Ignoring practical significance. A p-value below 0.05 is not enough. A difference of 0.2% between two groups may be statistically significant with a large sample but have no practical value. Always report effect size alongside the p-value.
Tips for getting better results
Use Minitab or Excel for calculations. Statistical software handles the complex calculations and produces graphical output that is easier to interpret than manual calculation. Minitab's Assistant feature guides you through test selection based on your data characteristics.
Run a normality test first. Before running a parametric test (t-test, ANOVA), confirm your data is approximately normally distributed. Use the Anderson-Darling or Shapiro-Wilk test. If non-normal, use the appropriate non-parametric equivalent.
Document the test in the project record. Include the hypotheses, test type, sample sizes, p-value and interpretation in the project documentation. This provides an audit trail for the decisions made in the Analyse phase.
Download the Hypothesis Testing Planner
A clean, editable Excel template for immediate use — structured, professional and ready to fill in.
Frequently asked questions
What is a hypothesis test?
A statistical test that evaluates whether observed differences are real or likely due to chance.
What is a p-value?
The probability of observing your results if the null hypothesis were true. Below 0.05 is typically statistically significant.
Which test should I use?
Comparing two group means: t-test. Comparing proportions: chi-square. More than two groups: ANOVA.
Statistical vs practical significance?
A result can be statistically significant but too small to matter in practice. Always check effect size alongside the p-value.
Advanced Toolkit Packs — available now
Structured, ready-to-use template packs designed for real improvement work. Pick the pack that matches your project and get started straight away.
Process Improvement Starter Pack
A starter pack for identifying improvement opportunities, measuring baselines and planning action.



Root Cause Analysis Toolkit
A practical RCA toolkit for defining problems, finding causes, validating evidence and creating action.



A3 Template Pack
A clean A3 problem-solving pack for concise, visual improvement thinking and follow-through.